Natural Language Generation
I had written a series of posts on my iLangGen framework last year. It aims to provide a flexible and expressive approach for building natural language generation systems. In today’s post, I would like to describe a concrete example of how iLangGen can be used for generating natural language text from structured data, aided by a convenient template text.
Here is the scenario. There is a pathology laboratory called XYZ Diagnostic & Scan Centre, which provides high-quality pathology services to the public. For example, it takes blood samples from patients and analyzes them under a controlled environment. Once the processing is complete, it is scrutinized by an in-house specialist, and the results are emailed to respective patients. Instead of merely printing a table of test names and results, XYZ Lab wants to make this more user-friendly by sending a personalized email that contains paraphrased data.
Let us see how we can do this. The overall approach is depicted in the following diagram.

The NLG application takes three inputs namely, a Template text file, a Grammar file and patient Database. It interacts with iLangGen passing the grammar file and additional context information, and subject to the overall structure of the template file, generates complete text for each database record.
First, here is the actual data (the data is stored as a CSV file for this demo):

Since this is just a demo, I have deliberately chosen a limited number of fields and records.
We use a template text to give us the overall structure of generated text. Here is the text we will use for this example:

Notice the sections appearing within the delimiters {{ and }}. Each such section has the format <GrammarName::Non-TerminalName> and is used by the application to guide iLangGen in generating appropriate text dynamicaly. The remaining text will be retained as it is. More on this later.
Here is the grammar part:
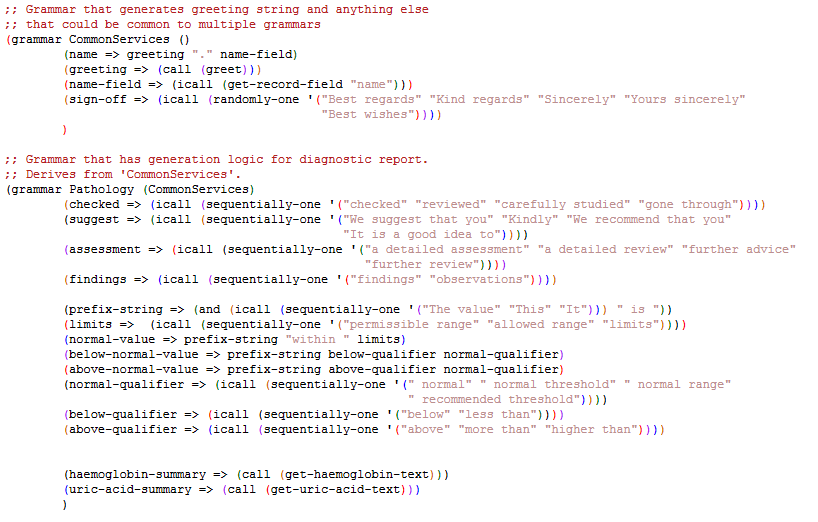
There are two grammars: CommonServices exists to provide greeting messages (could be enhanced later) and is inherited by PathologyGrammar. The latter contains the core logic for generating text customized for each patient. The function sequentially-one on the RHS of the rules returns one value from its list in the same order, each time it is called. When the last element has been fetched, it starts from the first element again. So, for example, the first time the non-terminal checked is visited, it returns checked. Next time, it returns reviewed, and so on. The fifth time it is called, it returns checked once again and the cycle starts. Thus, this function is useful if we desire guaranteed variation across consecutive generations. The other function randomly-one, used in CommonServices, returns one from its list of elements in random order. It is possible that this returns the same element across consecutive calls. We can choose either of the two functions depending on our requirement.
The function greet used in CommonServices emits the string Mr. or Ms. depending on the gender of the person denoted by the current data record.

Synthesizing text for haemoglobin value is handled by the function get-haemoglobin-text.

Depending on the person’s gender, age, haemoglobin value, and the recommended threshold, this function generates appropriate text.
In a similar manner, get-uric-acid-text generates text for uric acid level in the sample.

One interesting thing to note is the way these two functions call get-one-output-from-node, passing a non-terminal node name, in order to obtain another string dynamically from the same grammar.
For keeping the discussion brief, I have not optimized these two functions, but you can see that there is a lot of similarity in the code structure, and we could exploit that.
Let us take a look at the application now.

The three drop-down lists allow us to select the required inputs -Text template, Grammar and the Data file. Once the data file is selected, names of all patients are displayed on the left pane. When a patient is selected, his/her details are echoed at the bottom status bar, and the generated text is displayed in the main area. As we move from patient to patient, the text is refreshed automatically, and instantaneously!

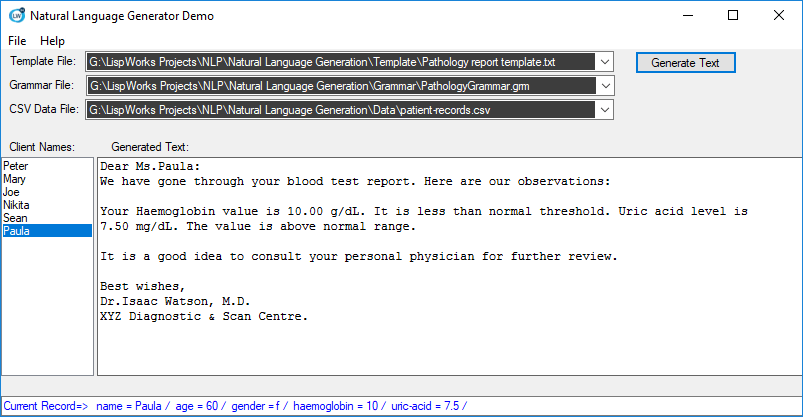
As you can see, the generated text varies from one patient to the next.
It is possible to design multiple templates and grammars for the same set of data. This allows us to achieve a much richer variety for the generated text. Obviously, that is the preferred solution when we wish to generate text in different languages for the given data.
An important practical usability concern arises here. If we build a system like this, who will design the template text and who will implement the grammar? Assuming that our end-user is XYZ Lab, it is fair to expect that they will prepare the template text because they know the domain and vocabulary. What about the Grammar file? Obviously, we cannot expect them to hire Lisp programmers, or needlessly outsource that task to another agency! Well, this can be handled by implementing a good front-end as part of the NLG system, which will be used by the team at XYZ Lab to specify the static text and embed meta representations of synonyms, paraphrased text and formula-based dynamic text schema. And because this is all Lisp, it is quite straightforward to generate the appropriate grammar on the fly!
One final note before concluding: For demo purposes, I have implemented this system as a stand-alone Windows-based application. In a real world scenario, where performance and scalability are important, one option is to turn this into a hosted REST API service.
iLangGen and the application discussed in this post have been implemented in LispWorks.
Hope you enjoyed reading this post!