Question Answering Using Dependency Trees
A few weeks ago I had written about my brief experiment with Mathematica’s new feature, which provides answers to questions based on given text. After that post, I spent some time thinking about how to implement something similar. In today’s post, I want to show you what I have been able to do in the last two weeks.
Here is what the QA system (a bit naive for now) will attempt to do:
(1) Given a piece of text, it will build an internal representation of the text
(2) When asked a direct question, it will find the sentences in the text, which match the question, and print the complete sentences
Let me elaborate item (2) further. A direct question is one that does not require inferencing, or looking beyond the given text for an answer. Suppose the text is Peter eats a lot of sweets even though he is diabetic, a direct question could be What does Peter eat?, but not What is diabetes?
Also, the system will print the complete matching sentence(s) even though the answer is contained in a part of the sentence. Thus, when asked the question What does Peter eat?, the system will respond Peter eats a lot of sweets even though he is diabetic, and not just Peter eats a lot of sweets.
Clearly, these are limitations, but we can live with these for now.
Dependency trees are used widely in NLP these days. Efficient parsers and 3rd party libraries are available for this purpose. Here is an example dependency tree for the sentence Peter likes salad.
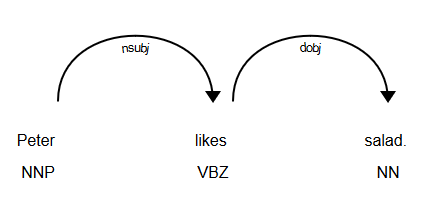
Here is one more example. The sentence Vicky is my pet dog will have the following representation:

My strategy is the following:
1) Parse the given text into dependency trees and prepare N-tuples of the form:
<sentence-id, dependency-label, head-word, tail-word>
2) Parse the question into a dependency tree and prepare N-tuples of the form:
<question-id, dependency-label, head-word, tail-word>
3) Convert all N-tuples to logical clauses for efficient matching/unification. I will be using LispWorks Lisp, which includes a Prolog engine.
Parsing the text and question into corresponding dependency trees can be done using spaCy or using commercial APIs such as TextRazor. I decided to use spaCy. This posed a minor challenge because it is a Python library, but my implementation is in Lisp. To facilitate the interaction, I wrote a Python REST server (using Flask framework) that would parse the submitted text using spaCy and send back N-tuples as result. This way, my Lisp program can easily communicate with the local REST server to parse the text.
For example, the sentence Vicky is my pet dog., when sent to the REST server, returns the following structure:
(DEFSENT S1 “Vicky is my pet dog.”
(NSUBJ “is” “vicky”)
(ROOT “is” “is”)
(POSS “dog” “my”)
(AMOD “dog” “pet”)
(ATTR “is” “dog”)
(PUNCT “is” “.”))
This structure will be evaluated by the Lisp client to build the Prolog-compatible clauses for further processing. In the same manner, all sentences of the given text as well as the questions will be converted to the above format.
OK, let us look at an actual interaction to understand how well the system performs.
First, we give the whole text (5 sentences in this example) and ask the system to build a model:

The function parse-text sends the text to the spaCy server running on the same machine and evaluates the returned N-tuples to build a model.
Let us ask a question:
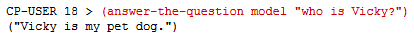
The function answer-the-question takes a model and a question. It sends the question to the server and gets an N-tuple of the question, and then passes it to the model to find a match for the question. If there is a valid match (multiple sentences could match a question), the result is returned.
Here are some more examples:



Notice how, for the last question, the system gives the complete sentence as reply although the best answer would be He is 5 years old.
Looks promising, isn’t it? Does it mean it is perfect? Of course not. Here is a simple question that the system is not able to handle:

What happened? Easy to guess. Whereas the actual text contains the pronoun He, the question uses the word Vicky, and hence the subject of the question and that of the potentially short-listed sentence do not match. This happens because we have not performed coreference resolution. This is a common requirement in any text understanding system.
For now, this is a good start. In the next post, I will discuss how we can address this problem.
Have a nice weekend!