Parsing Text with Apache OpenNLP
In my earlier posts I have written about parsing text using spaCy and MeaningCloud’s parsing API. For today’s article, I decided to take a look at OpenNLP, an open-source ML-based Java toolkit for parsing natural language text.
OpenNLP is a fairly mature library and has been around since 2004 (source: Wikipedia). It is actively maintained and developed, the current version being 1.9.1. It supports all the standard tasks expected of such a toolkit, namely, language detection, document categorization, lemmatization, tokenization, part-of-speech tagging, chunking, parsing, named-entity recognition, and coreference resolution.
In this article, my focus is on the parser alone. I will try to write about the other components in future articles.
The parser is a constituency parser and not dependency parser. It is thus similar to MeaningCloud but different from spaCy.
Getting started is quite simple. I downloaded the binaries from here.
I also downloaded two models: en-parser-chunking.bin and en-sent.bin from here.
The former is for the parser (chunking parser) and the latter is for sentence detection.
The parser parses one sentence at a time and hence we need the sentence detector if we are going to parse a text made up of multiple sentences.
I then configured my Libraries setting in IntelliJ IDEA to point to the downloaded lib directory. That’s pretty much it.
One interesting aspect of the parser is that you can specify the number of parses to return after parsing. Since the parser is ML-based, the system can typically arrive at multiple potential parse trees for the same sentence, each tree being associated with a probability factor (the official documentation defines this as the “log of the product of the probability associated with all the decisions which formed this constituent”.)
I wrote a simple wrapper class for testing the parser functionality. You can download the source from here.
To start with, let us print the parse tree for the sentence “John loves Mary.” asking for just one parse tree.

Here is the output:

When rendered as a tree, it looks like this (I used this site to render the s-expression):

This looks fine. Note the probability number. I assume this shows that what we have got is the best parse probable.
Next, let us ask for 10 possible parses for the same sentence:
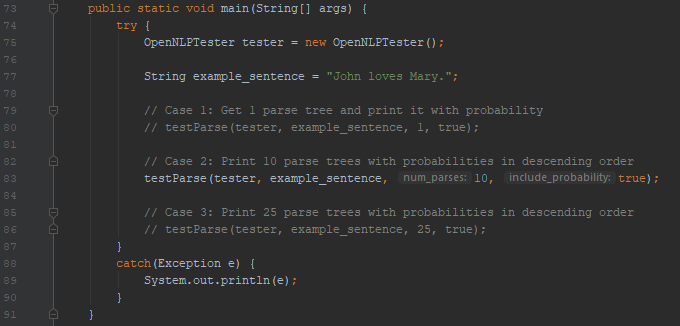
This is the output:

I have printed the parse trees in descending order of the probability, so the top one is the best parse in this batch. Notice that the top parse is not the same as the one we got earlier (when we asked for just one parse tree) and has lower probability number than the earlier one. It is not clear why this is the case.
In order not to clutter the screen, I am showing below the visual tree representation for the top two parses:


They do not look correct.
Just to understand what is going on, let us ask for 25 parses this time:

Here is what we get this time:

This time, it is interesting that the top parse tree corresponds to the one we got when we asked for the single parse case. The probability number also matches.
As a final confirmation, take a look at the visual representation of the top parse:

The trees match, right? It appears to me that we are better off asking for just one parse tree unless we are doing some study to compare the various outputs.
The result of parsing a sentence is a Parse array comprising as many parses as requested while parsing. The Parse class has several methods to access and manipulate the components of the parse structure, including accessing the child elements and so on. See the documentation for more details.
You can play around with my example code to get a feel for the parser functionality.
Have a great day and see you soon!