Named Entity Recognition (NER) with OpenNLP
In the earlier two articles, we looked at Sentence Parsing and Chunking as supported in OpenNLP. In today’s article, let us explore Named Entity Recognition, also known as NER.
NER is a technique to identify special categories of noun phrases such as people, places, companies, money, etc., present in the given text. This is widely used as part of information extraction. Here is a nice Youtube video on NER.
The two primary classes that are used for named entity recognition in OpenNLP are
- TokenNameFinderModel
- TokenNameFinderME
The former constructs a model from a model file, and the latter uses the model for entity recognition.
OpenNLP supports NER of the following categories:
- People
- Location
- Organization
- Date
- Time
- Percentage
- Money
Quite broad, I would say.
For the purpose of this article, I am going to work with the first three, namely, People, Location and Organization. It is easy to extend my sample code to include the others too, if you want.
First, we have to download the relevant model files. Here is a table that shows the model files I am using in my code:
People en-ner-person.bin
Location en-ner-location.bin
Organization en-ner-organization.bin
The following code snippet shows a sample session, working on three sentences.

The output is here:
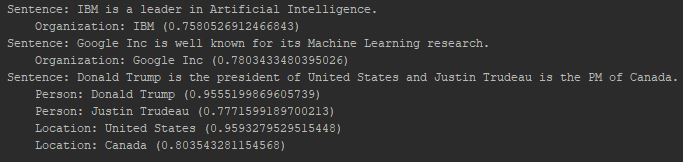
You can see that it is possible to get the entities as well the associated probabilities when using OpenNLP’s NER logic. I have defined two wrapper classes to make it easy to work with OpenNLP. Ideally, they should be moved to separate source files and made public, but for ease of demonstration, I put them all in the same file (and hence they are non-public).
Here are the wrapper classes:

It is quite easy to include support for the other named entities not covered in this example. You can download the source code from here.
Have a nice weekend!