Emotion Detection using ParallelDots API
Last week, I showed how we can use IBM Natural Language Understanding API to identify emotions from given text. Today, I would like to run through the same examples, but using ParallelDots API service.
There are wrappers in Java, Python, Ruby, C#, and PHP for accessing the REST service. However, I chose to write my own implementation in Lisp (you can get the program here). The core functions are shown below:
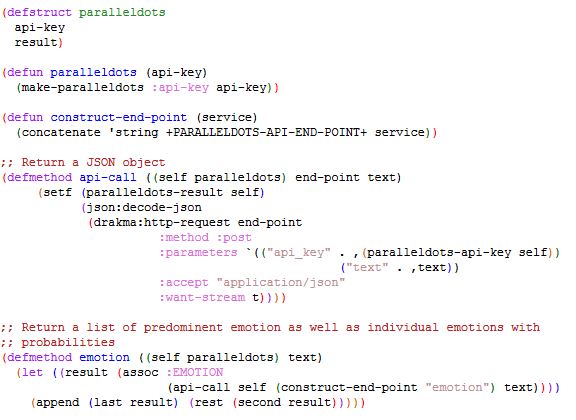
I think the code is self explanatory, so I won’t go into the details.
Before we try our sample sentences, we have to create a “paralleldots” object first:
CL-USER 1 > (setf pd (paralleldots +PARALLELDOTS-API-KEY+))
#S(PARALLELDOTS :API-KEY “<Key>” :RESULT NIL)
Substitute your API key instead of “+PARALLELDOTS-API-KEY+”.
Here is our first sentence:
“It was scary to drive alone on the highway.”
We submit this for emotion detection by invoking the “emotion” method:
CL-USER 2 > (emotion pd “It was scary to drive alone on the highway.”)
((:EMOTION . “Fear”) (:*FEAR . 0.57426417) (:*SAD . 0.35364214) (:*HAPPY . 0.0052627796) (:*ANGRY . 0.044279967) (:*EXCITED . 0.018575214) (:*BORED . 0.003975709))
The result contains the dominant emotion followed by the individual emotions. For some reason, even though the company’s web site lists seven emotions, the returned result contains only six emotions (the emotion “sarcasm” is not included).
As the above result shows, “Fear” (0.57) is the dominant emotion. I don’t understand why “Sad” (0.35) comes fairly close in the second place. If you recall IBM’s analysis for this example, “Fear” was 0.90 and “Sadness” was just 0.11. That appears reasonable.
The actual result returned by the API contains status code as well; for completeness, I have included a method to dump the actual result of the API call.
CL-USER 3 > (pprint (result pd))
((:CODE . 200)
(:EMOTION
(:PROBABILITIES
(:*FEAR . 0.57426417)
(:*SAD . 0.35364214)
(:*HAPPY . 0.0052627796)
(:*ANGRY . 0.044279967)
(:*EXCITED . 0.018575214)
(:*BORED . 0.003975709))
(:EMOTION . “Fear”)))
As you can see, the earlier shown result extracts just the emotion details from this more detailed result.
Let us move on to the next sentence:
“I can’t wait to see the President in person!”
Here is what the system says:
CL-USER 4 > (emotion pd “I can’t wait to see the President in person!”)
((:EMOTION . “Excited”) (:*FEAR . 0.27241874) (:*SAD . 0.03887309) (:*HAPPY . 0.29172024) (:*ANGRY . 0.04447313) (:*EXCITED . 0.34099433) (:*BORED . 0.011520461))
“Excited” is the main emotion. Again, “Fear” comes close and I don’t understand why. Even in IBM’s case, I had pointed out that the “Joy” factor was just 0.32, whereas it should have been higher in my opinion.
Now, the third sentence:
“The talk was dull and uninteresting. The audience was literally yawning throughout the program.”
The analysis is:
CL-USER 5 > (emotion pd “The talk was dull and uninteresting. The audience was literally yawning throughout the program.”)
((:EMOTION . “Bored”) (:*FEAR . 0.044667978) (:*SAD . 0.05334388) (:*HAPPY . 0.006943717) (:*ANGRY . 0.02137869) (:*EXCITED . 0.022493042) (:*BORED . 0.8511727))
Great. As expected, “Bored” (0.85) comes up on top. There is no disagreement here.
Let us check out the next sentence:
“Our whole family rejoiced when my son got the first prize.”
How does the API analyse this?
CL-USER 6 > (emotion pd “Our whole family rejoiced when my son got the first prize.”)
((:EMOTION . “Excited”) (:*FEAR . 0.121385224) (:*SAD . 0.068373315) (:*HAPPY . 0.31221092) (:*ANGRY . 0.08467515) (:*EXCITED . 0.38698116) (:*BORED . 0.026374208))
“Excited” (0.38) is the dominant emotion and “Happy” comes quite close (0.31). Perfect!
Let us look at the last example:
“I don’t understand why our politicians are so arrogant.”
Here is the analysis:
CL-USER 7 > (emotion pd “I don’t understand why our politicians are so arrogant.”)
((:EMOTION . “Angry”) (:*FEAR . 0.08077061) (:*SAD . 0.21222554) (:*HAPPY . 0.010213352) (:*ANGRY . 0.5890932) (:*EXCITED . 0.013984387) (:*BORED . 0.093712874))
“Angry” (0.58) predominates, with “Sad” coming at a distant second (0.21). This seems OK to me. In IBM’s case, we had “Disgust” (0.62) and “Anger” (0.38).
Overall, ParallelDots does a decent job of identifying emotions from the given text. Although my focus in this article has been on “Emotions“, they have APIs to handle “Sentiment“, “Abuse“, “Intent“, etc. The company has a “Free” plan that includes 1000 hits per day, which is quite sufficient for getting started and for exploring their offering. Do give it a try.
You can download my Lisp program from here.
Have a nice weekend!