Information Extraction Using spaCy’s Pattern Matcher
In the previous article, I explored the Deep Categorization capabilities of MeaningCloud. We saw how a powerful rule-based pattern matching language allowed us to map fragments of unstructured text to custom categories.
In today’s post, I want to go through spaCy’s pattern matching capabilities. The version I am using is 2.0.13. Some newer features are available in version 2.1, but I could not explore those.
There are essentially two matchers: Token Matcher and Phrase Matcher. The Token Matcher is well suited to match token sequences, whereas the Phrase Matcher is optimised for matching multi-word text, such as names of people and places.
I am going to use the same example as last time – patient case description, with slight enhancement.
Instead of using the Matcher class directly, I wrote a simple wrapper class named HomeoProcessor to provide a convenient abstraction. See the following:
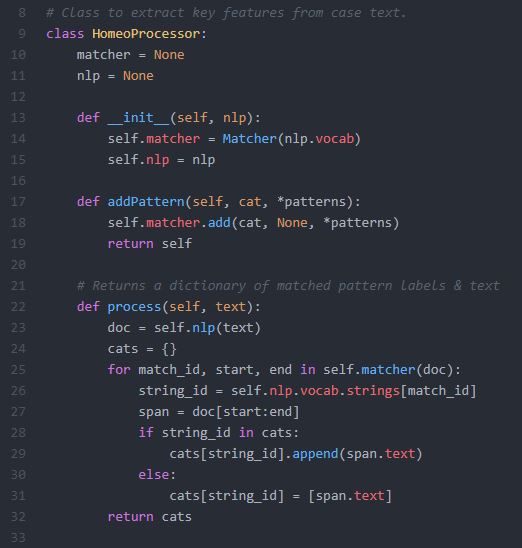
There is a method to add patterns and another to process the given text.
Next step is to define the various patterns we want to handle. I have defined simple patterns for detecting patient’s name, gender, age, and ailment.
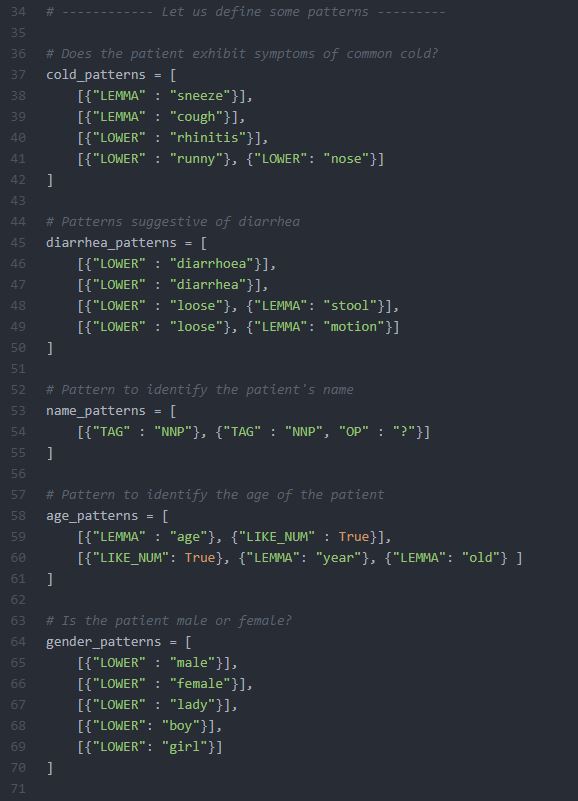
I guess the pattern definitions are self explanatory. Here is how we instantiate the class and use it:

We create an instance of the class first and bind the different patterns. We then invoke the process method, passing the case text. The function returns a dictionary of matched pattern labels along with the corresponding text.
Here is the output for the two example cases:

Seems to work as expected. spaCy allows us to attach custom handlers when matching patterns. For my example, I did not feel the need for these. Nor did I feel the need for Phrase Matcher in this case.
Although I could get the Matcher to do what I wanted, I feel the usability and design could be improved. It would be nice to be able to seamlessly combine token and phrase patterns using a unified syntax (instead of using separate Token and Phrase matchers) to build complex pattern expressions. Maybe also introduce “AND”, “OR” and “NOT” operators? These are not available in ver 2.1 as well. Something to think about.
Limitations apart, the nice thing is that this is available for free in a high-performance NLP engine that is continuously getting better.
The Python program can be downloaded from here.
Have a great day!