Using Definite Clause Grammars (DCG) for Information Extraction
In the previous article, I showed how we can use ATNs for extracting key information from natural language text. I also pointed out in that article that Definite Clause Grammars (DCG) are a more compact formalism for doing this. That will be the focus of today’s article.
For a nice introduction to DCG, read this.
Let us first define the ATN arc primitives in DCG. Here are the definitions:

The predicate is_cat interfaces with the lexicon to determine the part-of-speech category of the given word. Here is a simple grammar that demonstrates the use of wrd and cat primitives:

The sentence “The dog ran fast” is accepted by the above grammar:

In the second sentence, the verb “chased” is not followed by an adverb and hence it is not accepted.
The above grammar applies to the complete sentence, which is how we normally define and use DCG.
How can we use DCG to parse parts of a sentence? Additionally, how do we extract items of interest from a sentence? The following grammar identifies simple VP chunks:

We have used an additional argument in each grammar rule to retrieve the desired data during parsing. Here is an example using the chunking grammar:

As expected, the grammar correctly identifies the VP chunk “ran fast”. What happens if we process the sentence “He ran fast and ate well”? See below.

Interesting. The reason why we get the trailing VP chunk and not the first one is because when we invoke the predicate, we have indicated that we are expecting no tokens after the match. We can change that easily. Here is a predicate that collects all chunks:

When we apply this on the same sentence, we get both the VP chunks:

Using Registers
In the ATN implementation, we used registers as part of the structure building process. DCGs allow us to define additional arguments to suit our requirements and hence a separate Register system is not needed. However, it is easy to define a set of predicates to support the use of Registers. Here is the code:

It is possible to add more features, but I just wanted to give a hint as to how it can be done. The following grammar corresponding to VP chunks uses the Register system.

Here is the same sentence as before, but parsed as per the revised grammar:

You can see that the result is the same.
Information Extraction Example: Homeopathy
Now that you have a basic understanding of how to extract relevant information from a piece of text, let us look at a more interesting example. As in the previous article, let us try to extract the Age and Gender of the patient and Modalities of the disease from a homeopathic case record (simplified).
We will work with this text:

This text is stored in the file “sample-text.txt”. Here is the grammar to extract Age:

And here is the grammar to extract Gender:

Modality pattern is only slightly more involved than the above:
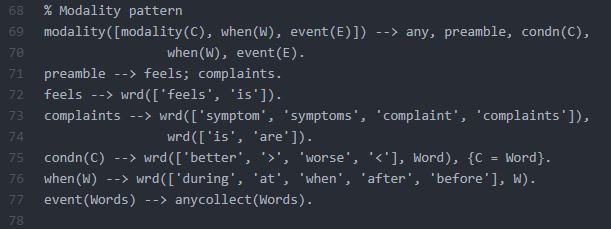
When we apply the above patterns to the sample text, this is what we get as output:

The actual Prolog code that does the processing is given below:
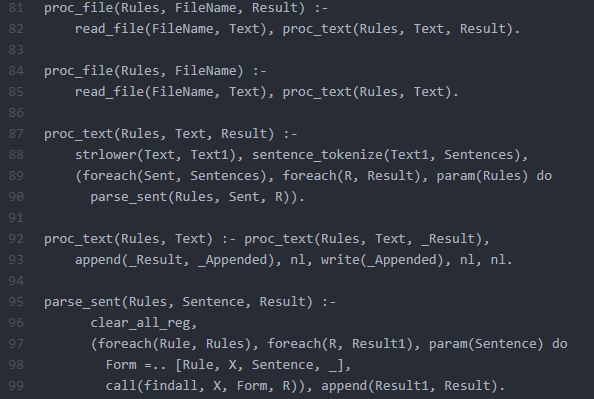
In order to save space, I have not included the predicates that tokenize the input text. That part is simple and straightforward.
As you would have gathered from the discussion so far, DCGs are a powerful formalism for processing both structured and unstructured text. All we need is a set of patterns to work with. The built-in backtracking mechanism of the Prolog engine makes the declarative model elegant and expressive.
I have implemented the above logic in Sicstus Prolog on Windows.
Have a great weekend!