lparallel: A Parallel Programming Library
You may recall that in the last article I had reviewed the book “Algorithms in Lisp” by Vsevolod Domkin. There was a reference to the lparallel library in Chapter 15 of the book. That immediately reminded me of the nice discussion of lparallel by Edi Weitz in Chapter 11 of his excellent book “Common Lisp Recipes”.
Since I have not used lparallel so far, I wanted to check it out. Instead of trying something very original, I decided to start with the “pmap” example in Edi’s book.
Here is the code for the “pmap” example:

I made a minor change to “test” and “ptest” to return “t” instead of the mapped result. This is to avoid the large data dump when I execute the function on the console. Of course, if I wanted to compare the results of the two maps, I would have retained the original code, but that was not my intention. My focus was on the speed up due to parallel execution.
Here is my environment:
1) Intel Core i7-7700 CPU @ 3.60 GHz, 32 GB RAM, Windows 10, 64-bit.
2) LispWorks 7.1.2 Enterprise Edition (64-bit).
In fact, before running the “pmap” test, I wanted to find out the number of CPU cores on my Windows machine. Interestingly, in Section 11-6, Edi Weitz gives a “CFFI”-based implementation that does the job. I decided to use that:

Here is what I get when I execute “(get-number-of-processors)”:

When using lparallel, we have to specify the number of worker threads to use as part of its “kernel”.
First, I ran “(test)” and “(ptest)” with 4 kernel threads:

Looking at the “Elapsed Time” field, we see that “ptest” is 3 times faster than “test”. To see the CPU utilization, I ran Window’s Task Manager. This is what I see when the “(test)” function is executing:

You will notice that the CPU utilization is not that great. When I run the paralel version, “(ptest)”, the situation changes:

You can see the significant jump in the CPU utilization and the reduction in time taken. Good, that shows lparallel is working!
By the way, “Cores” in the utilization chart refers to the “physical” (or actual) hardware cores in the CPU. “Logical processors” is the total number of threads that can run in parallel. If the hardware supports “Hyperthreading”, as is true in my case, then multiple threads can run on the same core in parallel. That is why on my 4-core machine, I am able to run 8 threads in parallel.
Let us now try the two functions with 8 worker threads.

What about CPU utilization with increased threads?
We do not expect “(test)” to have any impact:

Now see how it changes dramatically when running “(ptest)”:

We have 100% CPU utilization when the function executes!
Next, I wanted to try the classical “Fibonacci” computation using lparallel. Here are 3 versions of the implementation:

Explanation:
1) “fib” is the standard recursive implementation.
2) “pfib” uses the lparallel construct “plet”. This results in two parallel threads computing (fib n-1) and (fib n-2). When they are done, the result is summed and returned. Note that the two threads run the first defintion “fib”.
3) “pfib2” is an extreme case of parallelism. It uses “defpun” construct of lparallel to define a function that can automatically execute in a parallel thread. Additionally, it uses “plet” and makes recursive calls to itself! This results in creating a very large number of threads, unmindful of the hardware support available. This can slow down the computation significantly.
This is what happens when these functions are run:
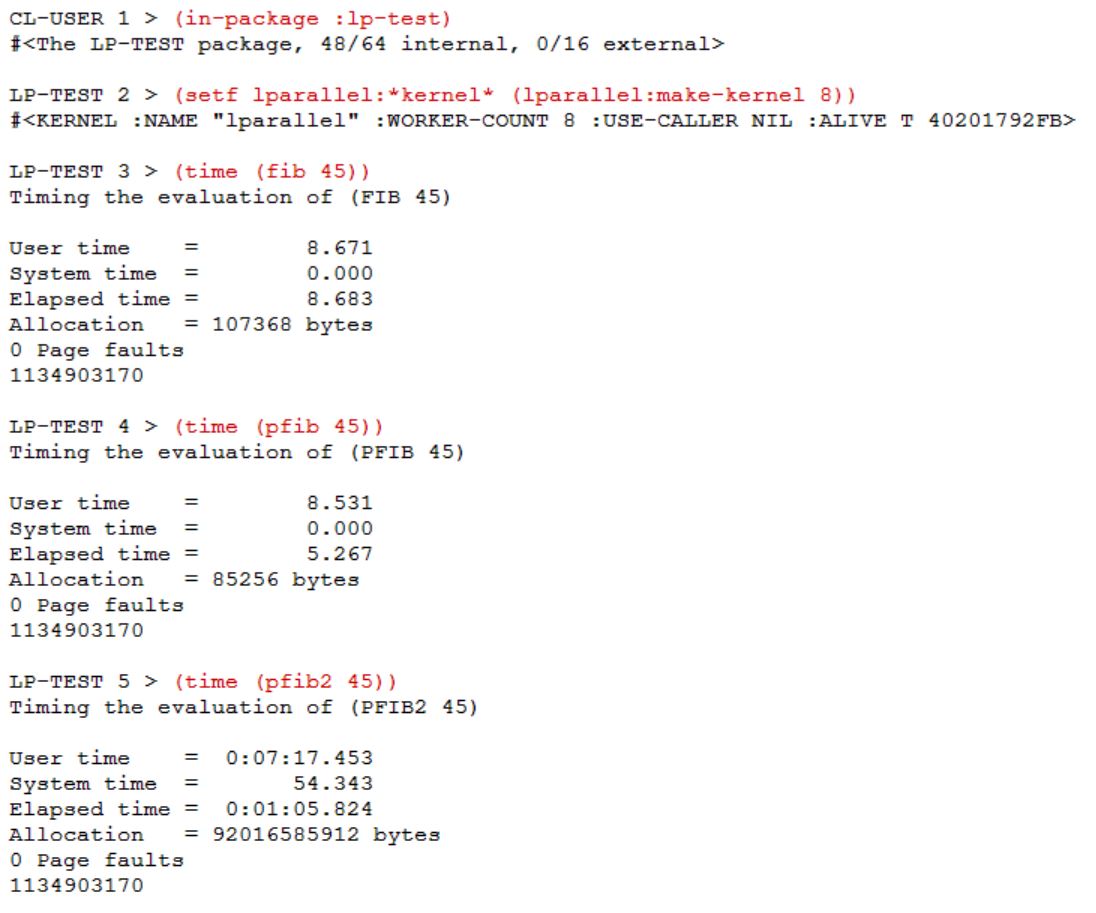
A look at the “Elapsed time” shows that “pfib” is faster than “fib” (by about 1.6 times), but “pfib2” is pathetically slow as expected!
That concludes today’s discussion on lparallel. It is a feature rich library and well documented. I intend to spend more time understanding its capabilities, and hope to apply it in one or more of my Lisp projects.
You can download the source code for today’s experiment.
Have a nice week ahead!